
Brief Thoughts On Machine Learning
Tue Jun 21, 2016So I'm through the first two units of the Udacity course. At this point, I've decided to outright refuse to do the coding projects, because
- they actively encourage the kind of absolute garbage code that is the bane of my proffessional existence1
- and also, they aim no higher than teaching you how to read the docs and call the API of one particular learning library, without imparting much additional understanding of its inner workings, design principles, or alternatives. Maybe this changes as we go, but I kinda doubt it.
The theory is still useful. Although, the trend I see being established so far2 is that all supervised learning consists of creating scatterplots and grouping things.
So I mean, cool and everything, and linear separators are a nice mathematical way to do that. But if the approach we're taking is "Plot things, and see where you can divide them", then it seems firstly like there are approaches other than separators (linear or curved) available, and secondly extremely important that the mapping function from your corpus to your n-dimensional space be sensical in some way.
Sensical Spatial Mappings
Sensical in the sense that there needs to be a non-trivial correlation to the original mapping. You likely wouldn't get useful results by taking a corpus of, for example, board game publishers, and assigning each a random x and y coordinate pair. You also very probably wouldn't get meaningful results by positioning them based on their alphabetical sorting, even though that's somewhat less arbitrary. It seems, in fact, that you'd have to choose your mapping function based on what questions you expect to ask of your system after training. For instance, if you wanted to build a recommendation engine for board games3, you might want to organize them somehow by grouping together publishers that tend to publish a similar library of games. Or you might group them by the typical weight or genre of the games they publish. So, you might want [Foxmind](http://www.foxmind.com/) to be near Iello, relatively far from Asmodee, and extremely far from both Stronghold and Level 99.
This is a non-trivial translation between two spaces, and it seems to me that it's possible to botch it badly enugh that your results will be bogus regardless of how effective and efficient your learning algo is. It also seems like it would be difficult to notice mistakes at this level. So I'm kind of confounded as to why the Udacity course hasn't spent any time talking about it. Hopefully, they'll have a thing or two to say later on, when we get into Unsupervised Learning.
Other Approaches
Very preliminary thinking ahead. You have been warned. I will almost certainly do quite a bit of related prototyping before too long.
See, it occurred to me while learning about the basic approaches that what we're really asking when we make a prediction is "Does this new datapoint map onto or near an existing point in our corpus". And if this is really what we're asking, then using linear or curved separators, as clever as it is, is just compensating for a lack of data. By the time we get to the kind of dataset shown here
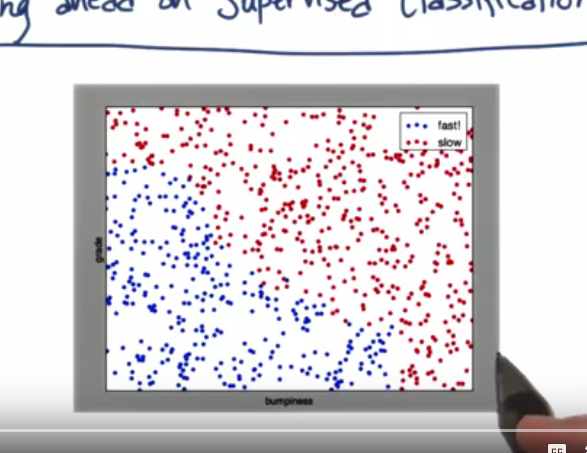
trying to plonk an arbitrary curve or line down to separate different labels might be doing more harm than good. Harm in the sense that the underlying implementation has to be mathematically involved enough that it needs to be abstracted away from human understanding. The "good" it's doing is that if we get a new outlier datapoint4, we can still take a guess at classifying it based on which side of the separation it falls on.
The trouble is, depending on how accurately your original problem space is being mapped into your n-dimensional grid, and what kind of distances are involved in making this new point an outlier, you might be guessing entirely. You might assign the right or wrong label purely by chance, rather than admitting that you have little basis for reasoning about this new situation and leaving the question of what to do with unlabelled data with a higher level of the system. Here's a couple ides for systems that don't trip over that particular obstacle.
Cellular Automata
Instead of drawing a line trying to separate points in your corpus, define some CA rules and iterate them until the steps become stable to some threshold. You'd want 2l types of cells for this automaton, where l is the number of labels involved. Actually labelled points, lets call them "seeds", spark life around them, while nearby points, lets call them "grass" propagate life into un-occupied territory. The occupied territory edge cases are where this approach would get fairly involved. You'd want something along the lines of
(let* ((seeds (group-by #'label (adjacent-seeds self)))
(grasses (group-by #'label (adjacent-grass self)))
(tied-seeds? (apply #'= (values seeds)))
(tied-grasses? (apply #'= (values grasses))))
(cond (not tied-seeds?)
(or (max-by-value-greater-than seeds *annex-threshold*) current-color)
tied-grasses?
current-color
t
(or (max-by-value-greater-than *annex-threshold* grasses) current-color)))
possibly taking more than directly adjacent coordinates into account. The point is that we want it to be possible, but non-trivial for new seeds to conquer territory. Possible, because we'll want to be able to drop new ones in later without necessarily re-running the full automaton from the start. Which implies that a seed labelled A dropped into a sea of B-labelled grass should be able to claw back some territory, depending on the proximity of the nearest B-seed.
There's a whole bunch of other mini-optimizations I could think of off the top of my head, but they mostly deal either with the same lack-of-data scenario5 I was griping about earlier, or they deal with trying to minimize the space usage of a running system6. Given the lessons I've learned, I'm not sure I want to dedicate brain-power to them right now.
What I do kind of want to think about is the ambiguous zones. That Udacity course has already pointed out many situations where, actually, a predictor is effectively going to be a guess at which label applies at what position in your translated space. This cellular approach gives you an elegant-seeming way of fighting that. Specifically, instead of having seeds fight it out on the border zones, you have the option of culturing separate petri dishes for each label, then doing separate hit tests on each one. If you happen to hit a seed on any dish, job's done, that's the most probable label. But you also have the possibility of hitting different grasses on different layers of the dish assembly, at which point you can resort to sorting the possible labels by confidence based on their distance from the nearest seed.
I'm honestly not sure how useful this would be, but the more I think about it, the more I think it'd be a lot of fun to build and play around with regardless.
Fuck Inference
Instead of trying to infer anything at all, via separators or some region-based automata approach, chuck the whole thing and just keep the initial points around. I'm not sure how far this would scale, since you'd eventually need to do something interesting for data-sets that can't fit into memory all at once, but that's a point of finesse for the moment, I think. When you get asked for a prediction on a fresh point
- Go find the
nclosest points in your data set to the fresh point - Tally them up, possibly weighing them by inverse distance from the fresh point
- Return the weighed list of possible labels for the fresh point (or possibly, only return the top one)
This doesn't run into any of the problems that we saw in the Cellular Automata approach, is trivial to teach incrementally, and seems like it would have a simpler data representation. The only downside, as I mentioned, is what the hell do we do with enormous training sets? There's a couple easy compression strategies that I could see off the top of my head, but if we're at "compression strategies", we may already be fighting a losing battle. It should be possible to distribute a system like this relatively easily7, but I'm not prepared to say much until I've built a couple and kicked the tires on each.
The approach also specifically doesn't fall into the wild-guess pitfall from earlier. We can do something like figure out the average distance between adjacent points during the learning process, and report a reduced confidence for points whose distance-from-nearest approaches or exceeds that distance. This would represent a reluctance to guess for predictions that deal with data which is sufficiently different from our existing datapoints that it invites speculation.
As I said, I'll very probably end up prototyping all of the above at some point relatively soon. I'll let you know how it all goes, with github links included.
EDIT:
So I went through the next few lessons so see what's in store. The thing I describe in the Fuck Inference section sounds like it's close to a classic technique called K Nearest Neighbors. Which is awesome, 'cause it probably means some people have already thought about any optimizations I might want to run on it, and figured out how to push it up to distributed systems. In other words, what I kinda want to do is very probably possible, so I'm not wasting my time by thinking through it.
There's still no real mention of the thought I had in the Sensical Spatial Mappings section. Again though, I'm just barely into unsupervised learning, so I'm sure there's stuff coming.
